







Table of Contents


How a configuration-based, no-code approach enabled Data Engineers to deploy pipelines faster and focus on data quality.
What is a Data Enrichment Pipeline?
Data enrichment is a process where data is enhanced and refined to increase its utility and value for business decision-making. This process typically involves merging external data from various sources with the user’s input. Data enrichment can be applied to various domains including CRM enhancement, lead scoring, risk analysis, and targeted marketing initiatives.
For instance, enriching basic company details — like the name and address — with Firmographic data such as revenue, number of employees, and NAICS code significantly enhances lead scoring processes within a CRM. Furthermore, this enriched data can be leveraged for training predictive models to assess the likelihood of a prospect converting into a paying customer, optimizing marketing strategies.

Assuming a user is looking for some financial aggregations, let’s review Yahoo Finance enrichment pipeline as an example: A user inputs a company name, it’s converted into a corresponding ticker symbol (AAPL, AMZN)— a crucial step for accurate data retrieval. Next, we access financial data through the Yahoo Finance API, fetching stock performance metrics. Key financial statistics are extracted by aggregating the raw data into monthly low, high, and average stock prices, and trading volume. This aggregation provides an informative summary, offering users insights into stock trends and market behavior within a specified timeframe.
Moreover, the pipeline might include recurring fetch-process cycles. The context can be utilized for deriving insights with LLMs. For example, is the company’s stock trending up or down?
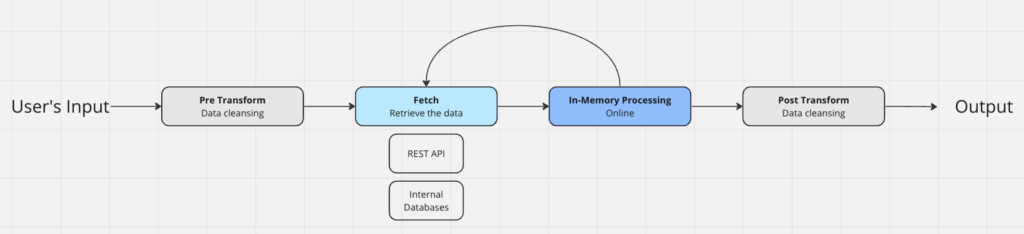
Functionality Requirements and Challenges By Step
Pre-Transform
Goal: validating, cleaning and normalizing the pipeline’s input.
Cleansing Data: Normalizing and correcting the input data, translating to a common language, improves the accuracy, coverage and reliability of the enriched data. Input from the user should be structured by their data types. Therefore, we run our internal Transformers, based on our internal data model:
| Trasformer | User’s Input | Normalized Output |
|---|---|---|
| TextToOrganizationName | Alphabet Inc. | alphabet |
| UrlToDomain | https://explorium.ai/data-catalog/ | explorium.ai |
| CountryToCountryCodeAlpha2 | United states of AMERICA | us |
| CountryToCountryCodeAlpha2 | united kingdom | uk |
- TextToOrganizationName: normalizing the company name into a more structured label with common suffixes removed, lower case, and cleaned.
- CountryToCountryCodeAlpha2 — USA, united states, United States of America are all distinct labels for the same entity: ‘us’.
Enhancing Data Accuracy: Verifying data elements like addresses, phone numbers, and emails to ensure they are current and correct. E.g. avoiding enriching a record with an invalid email.
Challenges: How do we make sure the relevant transformer is being used? How are transformer versions updated through all enrichment pipelines?
Fetching
Goal: retrieving data signals from internal or external sources.
- Internal Databases: Fetching the data from production databases such as PostgreSQL, DynamoDB, Elasticsearch or others. Note that an offline ETL (Extract, Transform, Load) process periodically updates these databases.
- REST APIs: querying various providers to collect data on the enriched record. The providers have different attributes: some might have strict concurrency limitations, different query methods or batch sizes.
Challenges: Managing database connections can be complex, especially when retrieving millions of records efficiently. In terms of external REST API calls, performance optimization is crucial. Implementing scalable concurrent API requests is essential. Employing retry mechanisms and rate limiters can improve the robustness of API interactions, while integrating a caching system can enhance performance.
In-Memory Processing
Goal: Data processing and imputation
For example, calculating the revenue per store if we have the number of stores and the total revenue, imputing missing details like company size by leveraging machine learning models based on fields such as company type and number of locations.
Challenges: How do we enable a no-code flexible process engine?
Post Transform
Goal: Verifying all signals are valid and converting them to correct data types, cast floats into integers, drop invalid data.
Common Infrastructure
Each step has challenges, especially when dozens of enrichments with similar and different steps are part of the pipeline. Addressing the complexities of each phase requires robust infrastructure. Moreover, deploying and maintaining a vast array of enrichments demands a strategic approach. When internal package versions are updated, the redeployment of all associated enrichments is often necessary. For this reason implementation of a standardized logging protocol across all pipelines to enhance monitoring capabilities is critical. Monitoring key performance indicators such as cache hit rates, API query counts, pipeline throughput, and latency is essential for maintaining system efficiency.
The Previous Infrastructure
Before the no-code infrastructure, there was a common Python abstraction class that included a fetch and process step. Each data engineer implemented their own pipeline Python code. Although there were shared packages for Querying APIs, querying the different Databases or running the transformers, the code was messy.
- Redundant Efforts and Inefficiencies: Due to the lack of visibility into others’ work, engineers often unknowingly duplicated efforts by solving the same problem in different ways. This wasted time, resources and led to inefficiencies in troubleshooting and maintaining code.
- Scalability Issues: As the business scaled and data volumes grew, the bespoke nature of each engineer’s pipeline led to scalability issues. Individualized solutions were not designed with scalability in mind, requiring significant rework to handle increased loads.
- Difficulty in Knowledge Transfer: The absence of standardized coding practices or shared knowledge repositories made it difficult for new engineers to onboard and understand existing pipelines. This hindered the sharing of best practices among team members, slowing down innovation and improvement.
- Compromised Data Quality Due to Misplaced Priorities: When data engineers focus primarily on performance, scalability, and error handling, data quality suffers. This neglect can delay the detection and correction of data issues, resulting in inconsistent data outputs that impact decision-making and diminish the overall value of the data.
- Complex and Inefficient Deployment Flow: Deployment processes were lengthy and complex, often requiring careful coordination to avoid conflicts and ensure consistency across services. Furthermore, scaling operations were typically focused only on the pipeline pods, leading to inefficient resource use. This approach led the development cycle to spread over days (and even weeks).
These points highlight the challenges and inefficiencies of having a fragmented approach and the importance of a no-code infrastructure to address these issues effectively.
Guiding Points for The New No-Code Infrastructure
To deal with those bottlenecks we decided to start a new no-code infrastructure project:
- Fast Development Cycle: The no-code infrastructure dramatically accelerates the development process. Developing a new enrichment pipeline now takes just a day or two, as opposed to the lengthy timelines of traditional coding methods. Moreover, bug fixes and feature additions can be completed and deployed to production within minutes to hours. This rapid development cycle enables more agile responses to business needs and technological changes.
- Maintenance and Monitoring: The new system simplifies maintenance and enhances monitoring capabilities. We have a common logging and tracing language, with shared facets and attributes between all the pipelines.
- Enrichment Pipelines as Configuration: By treating enrichment pipelines as configurations rather than code-heavy projects, the new infrastructure minimizes the complexities involved in managing individual components. This simplifies the development and maintenance of data pipelines and ensures that engineers are free from navigating the technical details of the underlying system. Instead, they can concentrate on optimizing data quality and functionality, ensuring delivered data products are high quality and meet business requirements.
- Scalability and Flexibility: The new infrastructure is designed to automatically scale per demand without focusing on a specific pipeline. This elasticity is an efficient use of resources, adapting to varying loads without requiring constant adjustments.
Components of a Good Abstraction
- Readability: The configurations are YAML based, which is more user-friendly than JSON. Additionally, we integrated custom YAML parsers that support features such as “include,” which allow for modular configurations. This modularity helps in managing complex configurations by breaking them down into reusable and manageable pieces, improving maintainability and readability.
- Structured and Modular Design: Each enrichment pipeline is constructed through a sequence of defined steps, adhering to a clear and logical structure. Every step is designed to utilize a specific resource, whether it be a REST API based resource, PostgreSQL, DynamoDB, DuckDB or any additional resource implemented. This structured approach ensures that pipelines are scalable and adaptable, allowing easy integration or modification of resources as business needs evolve.
- Efficient Development and Testing: Our approach centers on configurations rather than traditional code deployment, significantly streamlining the development and testing phases. Engineers can directly load and test configurations without the need to deploy code, leading to faster development iterations. We maintain a dedicated repository for these YAML configurations, which is integrated with CI system that ensures synchronization of the most current configurations across our environment.
Infrastructure Solutions
Multiple Integrations: To allow multiple integrations within our system we created an additional abstraction — a Resource. A resource is a way to define a data source. Each resource has a unique name and uses one of the available connectors. It is defined once and can be used in various steps or enrichment pipelines. Some of the available resources we have are a PostgreSQL, DynamoDB, Elasticsearch, DuckDB or any REST API provider.
name: google_geocoding
connector:
type: REST@v1
base_url: "https://maps.googleapis.com/maps/api/geocode/json"
auth:
type: api_key
parameters:
key: <my_api_key>
add_to: query_parameters
timeout_seconds: 10
retry_policy:
type: exponential
max_tries: 3
max_time: 60
batch_size: 1
concurrency: 1000The google_geocoding resource is configured to connect to Google’s Geocoding API using a REST connector. It utilizes a base URL specifically for fetching geocode data in JSON format. Authentication is managed through an API key being added to the query parameters of each request. Requests time out if they take longer than 10 seconds.
The retry policy is set to use exponential backoff, attempting a maximum of three retries with a total allowed time of 60 seconds for attempts. This policy helps in managing requests that initially fail, potentially due to API limits or network issues.
The system is configured to handle queries individually (batch size of one) since the Google Geocoding provider processes one query per record. The concurrency setting is high, allowing up to 1000 simultaneous requests, catering to high-volume data processing needs.
REST APIs: Implementing a robust abstraction for REST APIs might include some more advanced features such as a retry mechanism and policy for dealing with failed requests. A generic method to add the relevant parameters for each query (method type — GET/POST, a dedicated body, query params, headers or authentication). Some providers accept multiple records within the same query and required us to support some “map/reduce” mechanism. Some providers returns an HTTP success response (200) but the failure information is encapsulated within the response, which forced us to implement a status resolver.
Use DuckDB for Enhanced Data Processing Flexibility: In the previous infrastructure, data engineers enjoyed considerable flexibility allowing them to write Python code needed for tasks such as processing objects, merging data, importing external sources, aggregating, and handling exceptions. Seeking an effective alternative to maintain this flexibility, we decided to integrate DuckDB into our In-Memory Processing framework. DuckDB is specifically engineered for analytical query workloads, typical of online analytical processing (OLAP) scenarios. After evaluating common Python use cases in our operations, we concluded that DuckDB’s capabilities — enhanced by features like lambda and utility functions, pattern matching, and advanced text functions — allow us to replicate most Python functionalities using SQL queries. This adaptation ensures that our data processing remains robust and versatile.
Let’s see a demonstration of DuckDB’s capabailities. Here is an example of Google Geocoding API response — a nested JSON requiring further processing:
{
"results": [
{
"address_components": [
...
],
"formatted_address": "1600 Amphitheatre Pkwy, Mountain View, CA 94043, USA",
"geometry": {
"location": {
"lat": 37.4224428,
"lng": -122.0842467
},
"location_type": "ROOFTOP",
},
...
}
],
"status": "OK"
}Assuming we want to extract relevant fields only, we can utilize the DuckDB engine and build this SQL query to flatten the response.
select
results ->> '$[0].geometry.location_type' as "Location Type",
results ->> '$[0].geometry.location.lat' as "LAT",
results ->> '$[0].geometry.location.lng' as "LONG",
from {{_.data}}Chunk Size: Optimize the performance by splitting requested data into chunks and batches for fast and scalable fetching. Instead of running a sequential 500,000 records pipeline, data is split into smaller parallel chunks.
Template Engine: When crafting our system, we recognized that a simplistic configuration approach wouldn’t suffice for our developers’ needs. We opted to integrate Jinja Template Engine into our configuration framework for enhanced flexibility. SQL utilizing the Jinja Template Engine example:
-- social links
{%-
set social_platforms = ['twitter', 'facebook', 'linkedin', 'pinterest', 'youtube', 'instagram']
-%}
select
{% for platform in social_platforms -%}
trim({{ platform }}_link, '"') as {{ platform }}_link,
{% endfor %},
len(social_links) as number_of_social_networks
from {{ _.data }}Enrichment Pipeline No-Code Example
Finally, let’s have a look on a complete Google Geocoding Enrichment pipeline. The pipeline gets an input of type PostalAddress and enriches it with various geo-location attributes. The pipeline is built out of two steps — fetching the data from google API and post processing it with the DuckDB engine.
name: google_geocoding_api
pipelines:
- input_schema:
fields:
- name: PostalAddress
type: PostalAddress
steps:
- name: fetch
action:
type: rest@v1
resource_name: google_geocoding
method: GET
# Utilizing the Jinja Template Engine to
# add the input into the query parameters
parameters:
address: "{{_.data[0].PostalAddress }}"
# Demonstration of our 'include' feature
status_resolver: !include 'google_geocoding_api/status_resolver.sql'
- name: post_duck
action:
type: duckdb@v1
query: !include 'google_geocoding_api/post_transform.sql'
signals:
- Location Type
- Latitude
- Longitude
- Country
- Region
- Sub-Region
- US State
- County
- City
- Neighborhood
- Subpremise
- Street
- House Number
- Zip CodeThe new infrastructure provides Data Engineers with advanced, generic tools empowering them to design and implement robust and flexible data pipelines tailored to organizational needs. This approach shifts the focus from routine performance concerns to strategic data quality management.
Summary
In this article we showcased a configuration-based approach for developing complex data products, highlighting the shift from traditional, code-intensive methods to an innovative, no-code infrastructure. Data Engineers are now equipped with advanced tools allowing rapid development and deployment of data pipelines, drastically reducing the time from concept to production to a few hours. It simplifies maintenance, enhances monitoring, and allows for dynamic scaling.
This approach not only streamlines operations but empowers engineers to focus on data quality rather than managing infrastructure, fostering an environment where efficiency thrives.
The author is a Senior Backend Engineer @ Explorium, one of the architects of Explorium’s internal no-code infrastructure.






